Введение
Семантическая сегментация изображений заключается в выделении на изображении локальных областей (сегментов), соответствующих различным классам объектов. Сегментация снимков дистанционного зондирования Земли (ДЗЗ) находит применение во множестве областей: геоинформатике, инжиниринге георесурсов, автоматическом со- здании карт местности. Данная задача до сих пор не решена в полной мере и зачастую некоторые этапы процесса выполняются операторами вручную, что приводит к большим временным затратам и снижению эффективности. Среди существующего множества методов одним из наиболее эффективных подходов к решению данной задачи является применение нейросетевых алгоритмов. Существует определенное множество нейронных сетей (НС), используемых для сегментации изображений (SegNet, DeepLabv1-3+, PSPNet, U-Net), в которых применяются некоторые из следующих приемов:
– операция, обратная свертке, – развертка (deconvolution);
– расширенная свертка (dilated convolutions);
– многомасштабное агрегирование контекста (multi-scale context aggregator);
– формирование сети на основе пирамидального объединения (pyramid pooling network);
– марковские случайные поля (Conditional Random Field) и постпроцессинг
(postpro-cessing);
– пропуск соединения (skip-connection).
Архитектура сверточной нейронной сети (СНС) для сегментации U-Net использует первый и последний из перечисленных приемов: развертку (deconvolution) и пропуск соединения (skip-connection). Сеть U-Net является типичной структурой кодировщик- декодер. Кодер использует уровень объединения для постепенного уменьшения пространственного измерения входных данных, в то время как декодер постепенно восстанавливает детали и соответствующее пространственное измерение на уровне сети, таком как уровень деконволюции. От кодировщика к декодеру обычно существует связь, которая помогает декодеру лучше восстанавливать целевые детали. Типичная структура сети U-Net представлена на рис. 1.
Основные структурные изменения архитектуры произошли по сравнению с сетью FCN. Преимущество U-Net перед FCN заключается в том, что U-Net требует только од- ного обучения, а FCN – трех.
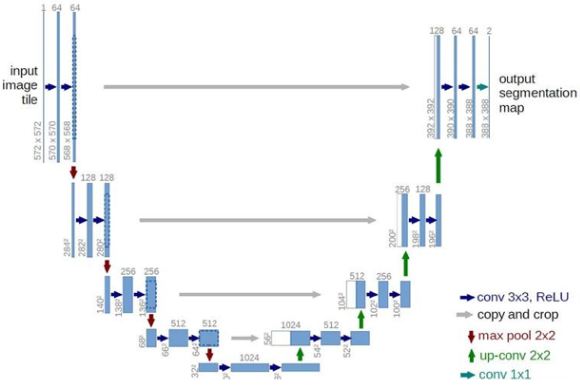
По результатам анализа следует отметить перспективность применения для семантической сегментации изображений ДЗЗ СНС U-Net. Она имеет простую архитектуру и, как следствие, малое потребление ресурсов при использовании в рабочем режиме и при обучении. Даже при небольшой обучающей выборке достигаются приемлемые по качеству результаты.
Построение модели обработки данных
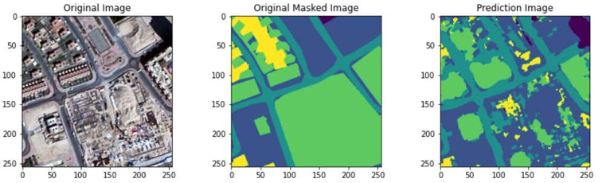
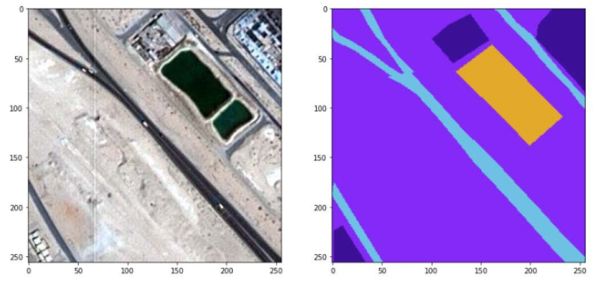
Исследования проводились с изображениями ДЗЗ (945 снимков с разрешением 838×859 пк). В тренировочном наборе 803 изображения, в тестовом – 142. Данные предоставил для использования Космический центр Мухаммеда бин Рашида (Mohammed bin Rashid Space Centre), в состав которого входит Эмиратский институт передовых наук и технологий, работающий над космической программой Объединенных Арабских Эмиратов. Пример исходного изображения и его маски приведен на рис. 2.
Для семантической сегментации были разработаны модифицированные модели сети U-Net на языке Python с использованием библиотек Scikit-learn, NumPy и SciPy, Pans и Matplotlib, Keras, Tensorflow. Tensorflow непосредственно выполняет обработку, а Keras помогает абстрагироваться от архитектуры НС, представленной в таблице.
Параметры модифицированной СНС
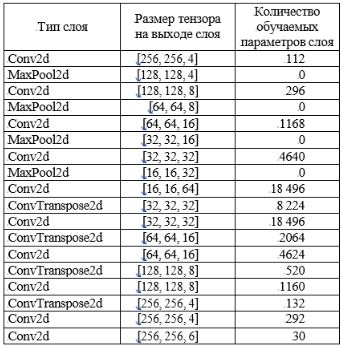
В качестве метода оптимизации используется Адам. Алгоритм его оптимизации является расширением стохастического градиентного спуска, который в последнее время получил широкое распространение для приложений глубокого обучения в области компьютерного зрения обработки естественного языка. Количество эпох обучения – 30.
Входными данными для обучения являются пары, состоящие из оригинальных изображений и размеченных масок (см. рис. 2). На масках определенным цветом обозначены области, которые соответствуют классам: «земельный участок», «дорожная сеть»,«строения», «растительность», «водоем». На них необходимо научиться сегментировать с помощью предложенной сети.
Для подготовки необходимого количества обучающих образов для разработанной НС выполнялись следующие действия:
1) загрузить входные изображения;
2) разметить области изображений в соответствии с целевыми классами;
3) задать входной размер нейронной сети;
4) задать размер области перекрытия;
5) разделить входные изображения на перекрывающиеся части размером, заданным в п. 3, и размером перекрытия, заданным в п. 4;
6) применить случайное изменение яркости и контраста;
7) добавить шум матрицы съемочной системы;
8) добавить случайный шум;
9) добавить артефакты сжатия изображений;
10) применить размытие изображения;
11) добавить оптические искажения;
12) применить упругую деформацию;
13) применить искажения по сетке;
14) применить аффинные преобразования;
15) применить случайное кадрирование с увеличением размера;
16) применить отражение по горизонтали;
17) применить отражение по вертикали.
Для пунктов 6–17 методики устанавливается некоторая вероятность выполнения пункта, которая должна быть меньше единицы.
Оценка обучения нейросетевой модели
В качестве метрики для оценки точности работы алгоритма выбрана Intersection- Over-Union (IoU), которая вычисляется по формуле
IoU = Si / Su
где Si – площадь пересечения результата сегментации и истинной области, Su – площадь объединения результата сегментации и истинной области. Точность при обучении на тренировочной выборке составила 83,8 %, на тестовой выборке – 82,4 %.
Пример исходного изображения, маски, сформированной по изображению, и соответствующего предсказания НС для маски показан на рис. 3.