При обработке изображений дистанционного зондирования Земли (ДЗЗ) требуется по некоторым признакам выделять (идентифицировать) некоторые однородные области изображения, причем, как правило, это подобие нечеткое и часто нарушается, т. е. в общем случае имеют место идентификация и последующее распознавание в условиях неполной и нечеткой информации.
Повышение точности идентификации и последующего анализа объектов может быть обеспечено за счет особенностей анализируемых объектов в структуре нейронной сети, т. е. разработки гибридных (комбинированных) нейросетевых архитектур либо построения ансамблей нейронных сетей. Гибридная технология предполагает сочетание традиционных, нейросетевых и иных интеллектуальных методов обработки, которые позволяют создавать эффективные системы принятия решений при обработке сложноструктурированных данных, когда использование лишь одного метода не позволяет учесть все характерные особенности объекта.
Цель работы – исследование возможности использования аппарата ансамблей искусственных нейронных сетей с применением решающих правил по прецедентам для идентификации объектов на изображениях поверхности Земли для повышения достоверности идентификации.
Так как основная гипотеза идентификации основана на разнице отражательной способности объектов земной поверхности, то необходимо собрать как можно больше данных об объектах. К примеру, если в качестве объекта рассматривается некоторая область сельскохозяйственной растительности, изображения ДЗЗ должны отображать развитие растительности на разных этапах: посев, активная вегетация, различные даты сбора урожая для разных культур.
Разработка модели
Разрабатываемая модель комбинирует нейросетевой подход и распознавание по прецедентам. Обрабатываемыми данными являются дескрипторы сложноструктурированных объектов на изображениях ДЗЗ, представляющие собой массив из 304 чисел с плавающей запятой, являющихся сжатым представлением участка цветного изображения размером 128×128 пикселов. Вычисление дескрипторов основано на использовании иерархического нейросетевого автоэнкодера. Отличительными особенностями дескрипторов является использование для обучения автоэнкодера мультимодальных многозональных изображений. При этом каждый из получаемых дескрипторов представляет собой прецедент, наборы которых могут быть использованы для обучения модели идентификации.
Предлагаемая для идентификации нейронная сеть представляет собой полносвязную многослойную сеть, которая принимает на вход отобранный набор признаков, получаемых из исходного дескриптора. На выход выдается вектор степеней соответствия входного дескриптора целевым классам. Алгоритм обучения: Adam [3] c параметрами lr = 0,0001, beta_1 = 0,9, beta_2 = 0,999, epsilon = 1P-8P, decay = 0,0 [4]. Функция потерь (loss) – categorical_crossentropy.
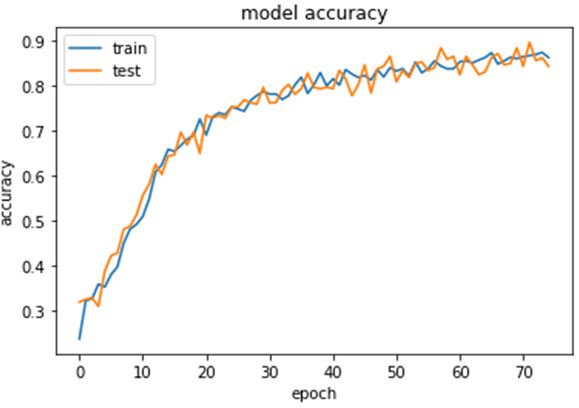
Соответствующая кривая значений точности при обучении изображена на рисунке.
Тестирование и оценка модели
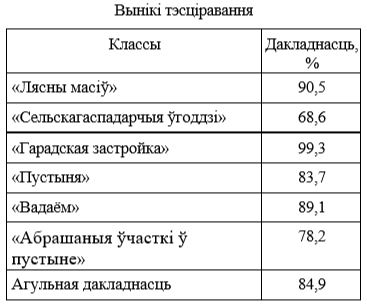
Тестирование программной реализации осуществлялось на выборке изображений четырех классов: «Лесной массив» (С1), «Сельскохозяйственные угодья» (С2), «Городская застройка» (С3), «Пустыня» (С4), «Водоем» (С5), «Орошаемые участки в пустыне» (С6). При этом оценивалась точность как для каждого класса в отдельности, так и для всех классов в целом. Полученные результаты приведены в табл. 1.
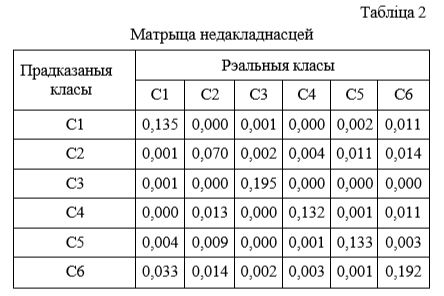
Из-за несбалансированности классов в исходных данных требуется дополнительная оценка. Полученные в результате этой оценки данные сведены в матрицу неточностей (confusion matrix) (табл. 2). Значения в матрице – это отношение количества пикселов, принадлежащих классу, к общему количеству пикселов всех классов в выборке.
Для оценки качества работы ПО были вычислены соответствующие значения точности (Precision), полноты (Recall) и F1-меры [5] (табл. 3).
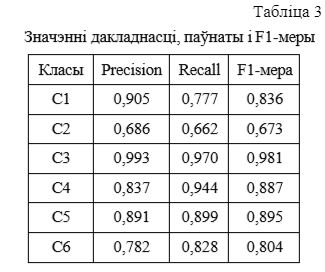
На данной выборке изображений некоторое количество ошибок идентификации возникло в связи с некорректным отнесением изображений класса «Сельскохозяйственные угодья» (С2) к классам «Пустыня» (С4) и «Орошаемые участки в пустыне» (С6), а также изображений класса «Лесной массив» (С1) к классу «Орошаемые участки в пу- стыне» (С6).
Разработанную модель отличает использование предварительного анализа прецедентов, формирующих обучающую выборку, что позволяет оптимизировать размер входных данных.