Уводзіны
У апошнія гады інтэнсіўна распрацоўваюцца сістэмы распазнавання, устойлівыя да малюнкаў, на якіх твар закрыты чымсьці (маскай). Наяўная інфармацыя аб сістэмах відэаназірання ставіць пад сумнеў эфектыўнасць існуючых класічных падыходаў да распазнавання асоб, бо яны заснаваныя на мадэлях, натрэніраваных на тварах без масак. Асноўныя падыходы да распазнавання асоб у масках грунтуюцца на распазнаванні бачнай часткі асобы. Прапанаваны аўтарамі новы падыход складаецца з наступных крокаў: – выявіць і сегментаваць медыцынскую маску на малюнку; – сцерці маску на ўваходным малюнку, выкарыстоўваючы вынікі сегментацыі; – аднавіць твар пад маскай на апрацаваным малюнку; – для распазнавання атрыманага твару без маскі прымяніць любы існуючы падыход да распазнавання асоб. Ніжэй больш дэталёва разгледжаны асноўныя этапы дадзенага падыходу.
Сегментацыя малюнка маскі
Мадэль для сегментацыі.
Першым этапам падыходу з’яўляецца сегментацыя маскі на малюнку твару. Была абрана нейрасеткавая мадэль UNet, спецыяльна распрацаваная для сегментацыі медыцынскіх малюнкаў. Архітэктура складаецца са сціскальнай часткі, пабудаванай па прынцыпе класічнай скруткавай сеткі, і расцягваючай, якая складаецца з узрастаючых скруткавых слаёў і ReLU актывацый.
Стварэнне трэніровачнага набору даных.
Набор даных для трэніроўкі сегментатара маскі на твары павінен складацца з пар малюнкаў (малюнак асобы ў масцы, бінарнае адлюстраванне маскі). На дадзены момант у вольным доступе не існуе такога набору даных, таму аўтарам прыйшлося ствараць яго самастойна. За аснову быў абраны інструмент ад FaceX-Zoo, які выкарыстоўвае ключавыя кропкі твару і UV-пераўтварэнне для рэалістычнай апрацоўкі. У якасці зыходнага набору даных узяты CASIA-WebFace. Атрыманыя штучныя малюнкі былі дапоўнены 400 малюнкамі з рэальнага свету, якія ўдалося сабраць з розных набораў даных для сегментацыі частак твару чалавека.
Арганізацыя працэсу навучання і вынікі сегментацыі.
Для мадэлі сегментацыі UNet была ўзята рэалізацыя Pytorch-Unet. Навучанне праходзіла ў два этапы. Спачатку праводзіліся тры эпохі навучання на падмностве штучнага набору даных у масках, які складаецца з 200 тыс. На гэтым этапе мадэль убачыла велізарную колькасць твараў, але навучылася сегментаваць толькі штучныя маскі. Затым яна была данавучана на працягу дзесяці эпох на камбінаваным наборы даных з асобамі ў масках з рэальнага свету, які складаецца з 1400 малюнкаў. Выніковы валідацыйны Dice-каэфіцыент склаў 0,982. Вынікі сегментацыі тэставых малюнкаў прыведзены на мал. 1.

Мал. 1. Вынікі сегментацыі на аўгментаваных (злева) і рэальных (справа) малюнках
Праведзеныя эксперыменты паказалі, што сегментацыя выконваецца дастаткова добра як на тэставых малюнках, дзе маска надзета штучна тым жа спосабам, што і ў трэніровачным табары даных, так і на тэставых малюнках з рэальнага свету.
Аднаўленне твару пад маскай
Мадэль для генерацыі твару.
Другім этапам падыходу з’яўляецца аднаўленне твару пад маскай на ўваходным малюнку па бінарнаму сегментацыйнаму адлюстраванню з дапамогай генератыўнай спаборнасці нейроннай сеткі. Выбар мадэлі праходзіў па выніках спаборніцтва па такіх крытэрах, як высокая якасць генерацыі і высокая хуткасць працы. Найлепшы вынік паказала мадэль DMFN (архітэктура прадстаўлена на мал. 2), якая і была ўзятая за аснову.

Мал. 2. Архітэктура мадэлі, якая выкарыстоўваецца для генерацыі твару пад маскай
Стварэнне трэніровачнага набору даных.
Набор даных для трэніроўкі генератара твару пад маскай павінен складацца з малюнкаў звычайных твараў без масак і бінарных масак, адпаведных медыцынскім маскам, якія нібыта надзетыя на твар. Для гэтых мэт выдатна падыдзе раней створаны і апісаны ў папярэднім пункце штучны набор даных для трэніроўкі сегментацыі маскі на твары на базе CASIA-WebFace. Прыклад пар малюнкаў трэніровачнага набору даных прадстаўлены на мал. 3.

Мал. 3. Прыклад пар малюнкаў набору даных, выкарыстаны пры трэніроўцы генератыўнай сеткі
Арганізацыя працэсу навучання.
Для трэніроўкі генератара DMFN выкарыстоўвалася яго аднайменная рэалізацыя, пераднавучаная на аднаўленне адвольных малюнкаў па адвольна размешчанай прамавугольнай масцы. Памер трэніровачнага набору даных склаў 200 тыс. малюнкаў. Малюнкі былі змененыя да памеру 256х256. Навучанне праходзіла восем эпох з памерам мілібатча 4 на відэакарце NVidia GeForce RTX 3060ti і заняло каля 12 гадзін. Learning rate для генератара і дыскрымінатара былі аднолькавымі і склалі 0,0002. Праз кожныя 100 тыс. мінібатчаў Learning rate памяншалася ў дзесяць разоў. Выкарыстоўвалася L1-рэгулярызацыя.
Вынікі эксперыментаў
Вынікі зняцця маскі з малюнка твару прадстаўлены на мал. 4.
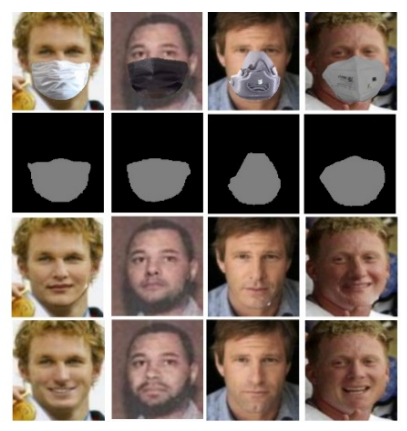
Мал. 4. Прыклады зняцця маскі з малюнка твару на малюнках штучнага тэставага набору даных Labeled Faces in the Wild прапанаваным падыходам. Зверху ўніз: уваходны малюнак, вынік “прадказаная маска”, згенераваны малюнак, сапраўдны
З мал. 4 відаць, што інструмент упэўнена сегментуе маскі на дадзеным наборы. Што тычыцца генерацыі твару, то атрымалі вынік праўдападобнага чалавечага твару, адпаведнага адкрытай яго частцы. Больш за тое, прайграны нават некаторыя асаблівасці, такія як форма носа, рота, што спрыяе паляпшэнню якасці распазнавання. Вынікі апрацоўкі набору даных з тварамі ў масках з рэальнага свету прадстаўлены на мал. 5.

Мал. 5. Прыклады зняцця маскі з малюнка твару на малюнках рэальнага тэставага набору даных Masked Face Recognition прапанаваным падыходам. Зверху ўніз: уваходны малюнак, вынік “прадказаная маска”, згенераваны малюнак
Выніковыя параўнальныя вынікі распазнавання твараў прапанаваным падыходам на базе атрыманага інструмента прадстаўлены ў табл. 1.
Табліца 1
Параўнанне дакладнасці распазнавання прапанаваным падыходам з існуючымі падыходамі
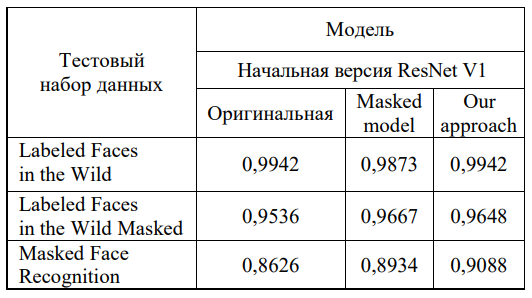
Па сукупнасці вынікаў на трох тэставых наборах даных прапанаваны падыход дэманструе найлепшую якасць распазнавання. Галоўным дасягненнем з’яўляецца тое, што ён не саступае арыгінальнай мадэлі, узятай за аснову, у распазнаванні звычайных твараў, але пераўзыходзіць яе ў распазнаванні твараў у масках. Параўнанне прапанаванага аўтарамі падыходу з падыходам MobileNetV2 прадстаўлена ў табл. 2.
Табліца 2
Параўнанне падыходаў у паказчыках, %
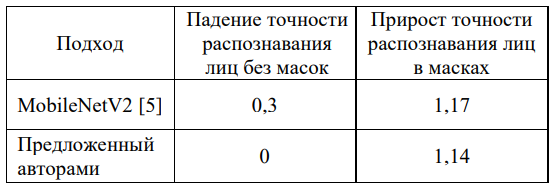
У заключэнне можна сказаць, галоўная перавага прапанаванага падыходу – тое, што ён забяспечвае паляпшэнне дакладнасці распазнавання твараў у масках без шкоды распазнаванню твараў без масак, у той час як усе разгледжаныя раней падыходы альбо не прыводзяць такіх даных, альбо дэманструюць пагаршэнне якасці распазнавання твараў без масак. Дадзеная ўласцівасць гэтага падыходу дасягаецца тым, што прапанаваны мадэлі, якія здымаюць маску з твару чалавека і аднаўляюць твар пад маскай у спалучэнні з існуючымі мадэлямі распазнавання твараў. Такім чынам, працэс распазнавання твараў без масак застаецца без змен.